Redes Neurais
- Redes Neurais Artificiais
- CNN
- RNN
Redes Neurais Artificiais
Redes Neurais Artificiais
Modelo computacional inspirado no cérebro humano, composto por unidades simples chamadas neurônios artificiais.
- Processamento paralelo
- Capacidade de generalização
- Aprendizado a partir de dados
- Modelagem de funções complexas
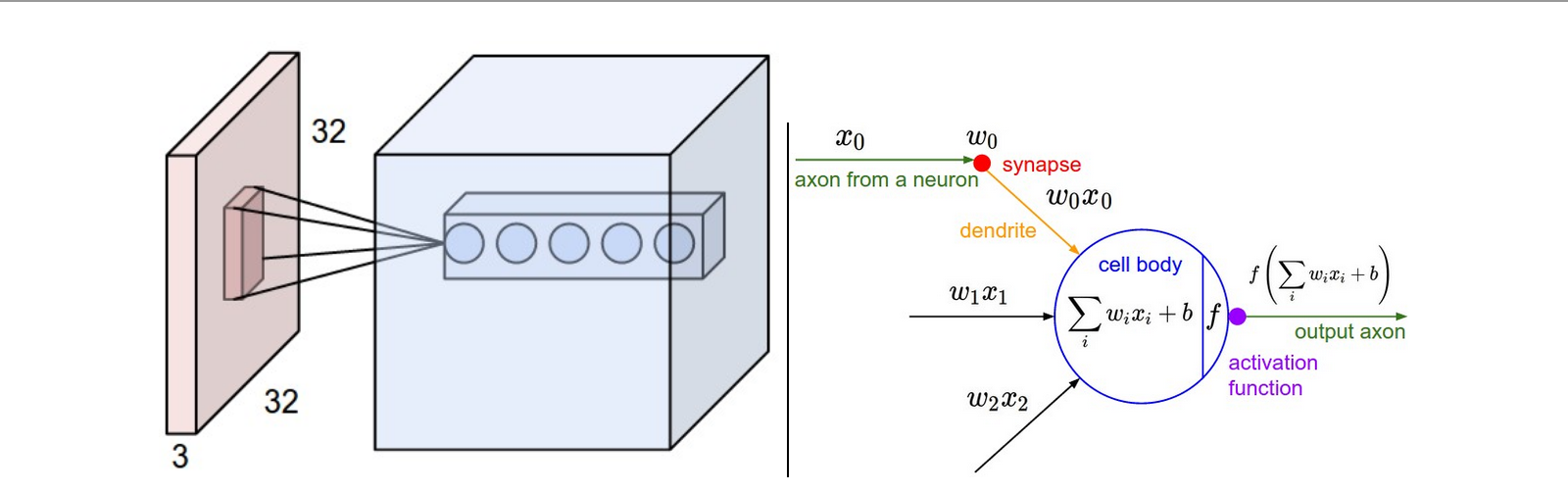
Neurônio Biológico vs Artificial
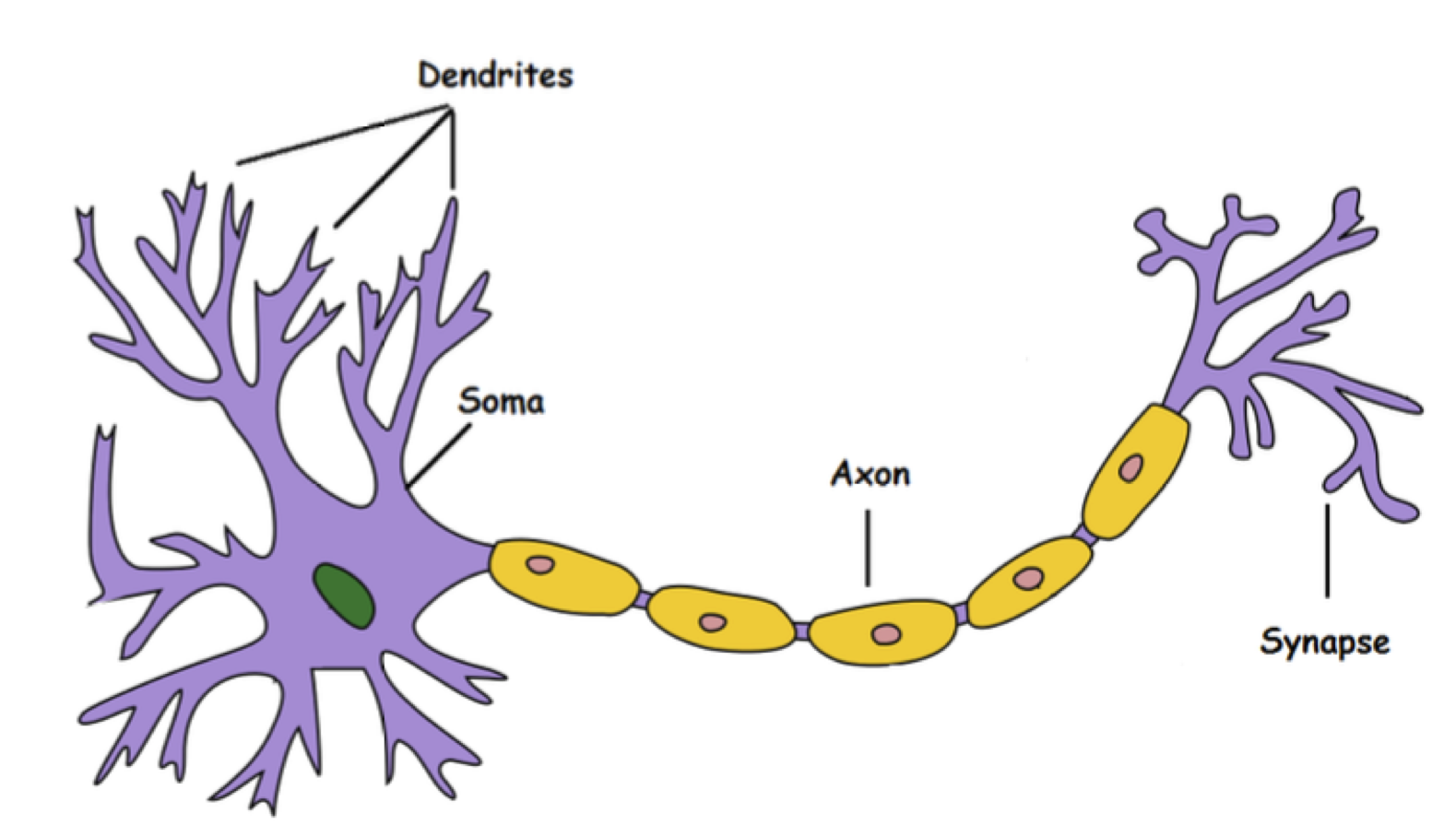
- Dendritos → Entradas
- Sinapses → Pesos
- Corpo celular → Soma ponderada
- Axônio → Saída
- Quadro
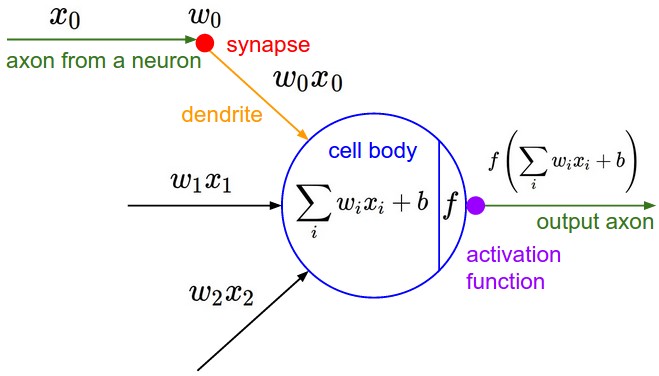
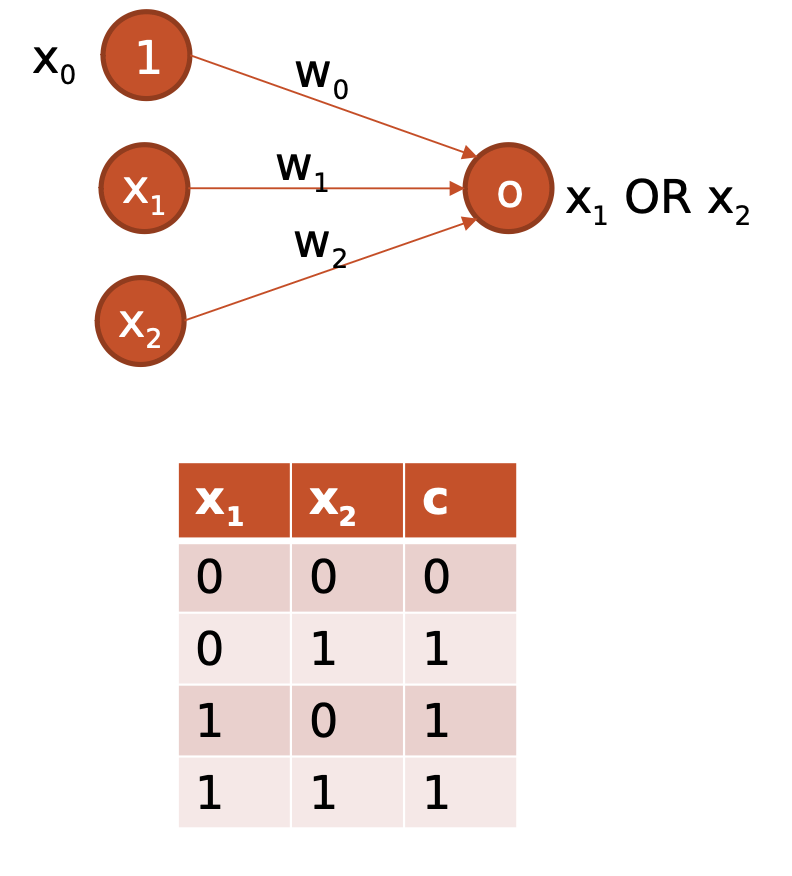
Perceptron
- Primeiro modelo funcional de rede neural
- Resolve problemas linearmente separáveis
- Base das redes modernas
Características
- Entradas ponderadas.
- Função de ativação.
- Saída binária.
Modelo
Funções de Ativação
- Sigmoid
- Tanh
- ReLU
- Softmax
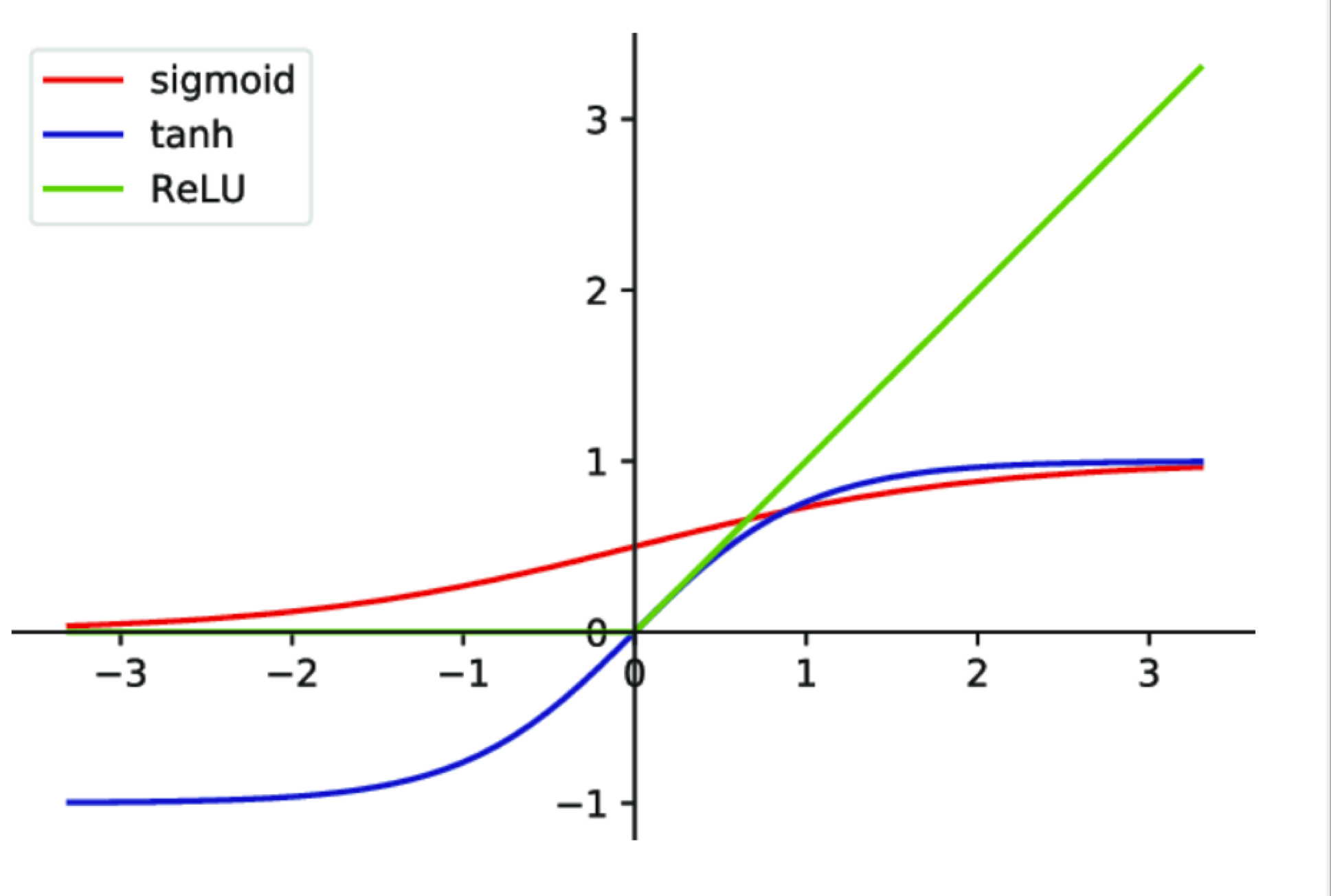
Não Lineares!
Por que Não Linearidade?
Sigmoid
\( y = \frac{1}{1+e^{-x}} \in [0,1] \)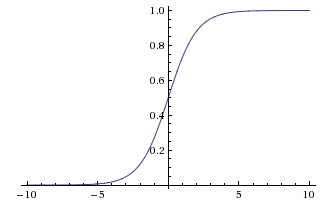
- Saída entre 0 e 1
- Interpretação probabilística
- Sofre com saturação
Problemas da Sigmoid
- Gradientes desaparecem nas extremidades
- Saídas não centradas em zero
- Treinamento mais lento
ReLU
\(f(x) = max(0,x)\)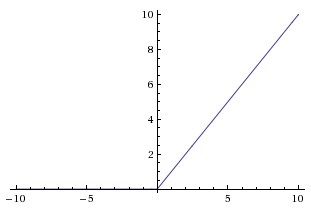
- Treinamento muito mais rápido
- Não satura para valores positivos
- Padrão
Vantagens da ReLU
- Computacionalmente eficiente
- Acelera o gradient descent
- Excelente desempenho prático
- Reduz o problema do gradiente desaparecendo
Problema da ReLU
- Gradiente zero permanentemente
- Comum com learning rates altos
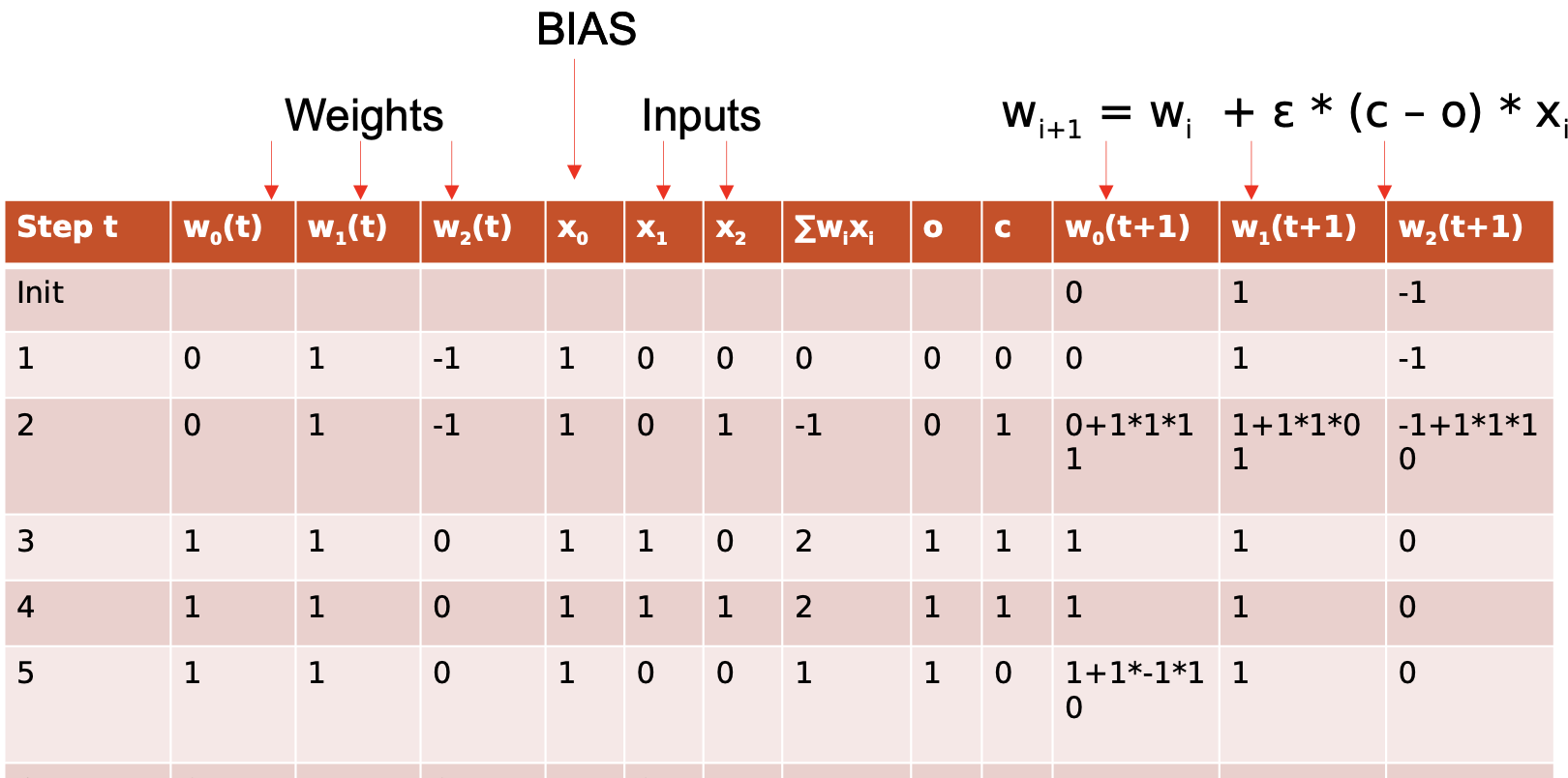
Aprendizado
Randomly initialize the weights wi
While TRUE
Take a example (x,c) from S
Calculate the output o fo the network for the input x
Update the weights of the network as follows:
for i in [1, n]:
wi = wi + * (c - o) * x ɛ i
end for
End while
Learning example
Activation function :
Heavyside
f(x)=1 if x>0,
f(x)=0 otherwise
Learning rate: ɛ = 1
Limitações do Perceptron
- Não resolve XOR
- Necessidade de camadas ocultas
- Origem do Redes Neurais Artificiais Profundas (Deep Learning)
Redes Neurais Artificiais Profundas
O que são Redes Neurais Artificiais Profundas?
- Aprendem representações hierárquicas.
- Grande poder de generalização.
Arquitetura Multicamadas
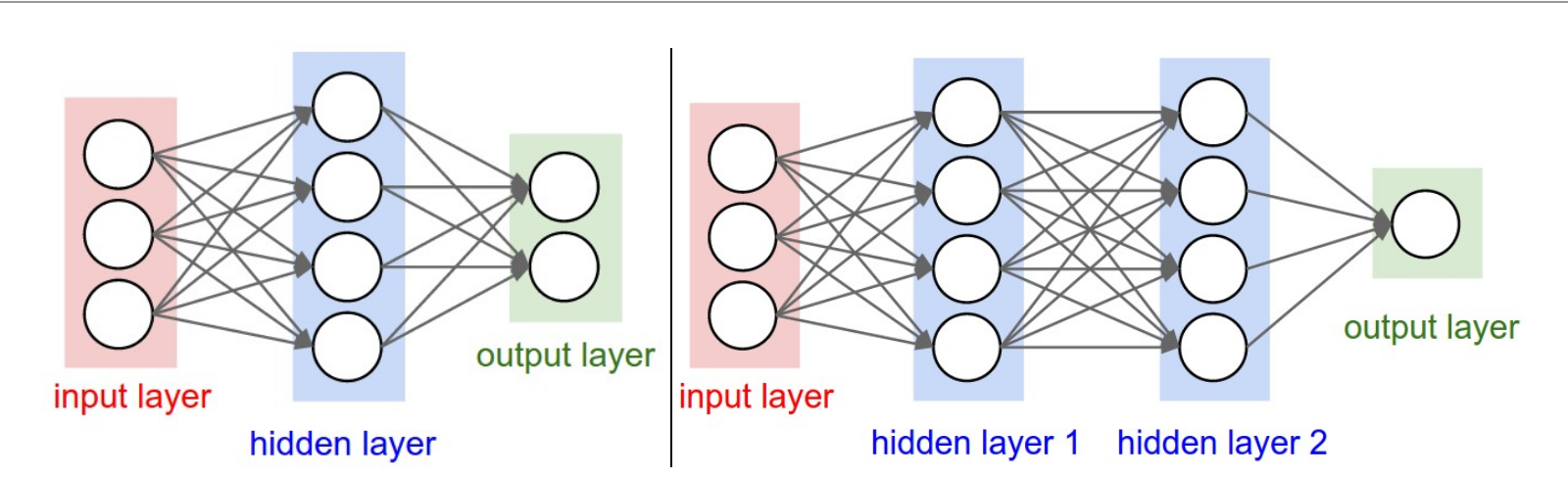
- Camada de entrada
- Camadas ocultas
- Camada de saída
Aprendizado Hierárquico
- Camadas iniciais: características simples
- Camadas intermediárias: padrões
- Camadas profundas: conceitos abstratos
Poder de Representação
- Podem aproximar qualquer função contínua
- Desde que tenham neurônios suficientes
Mais Neurônios, Mais Capacidade
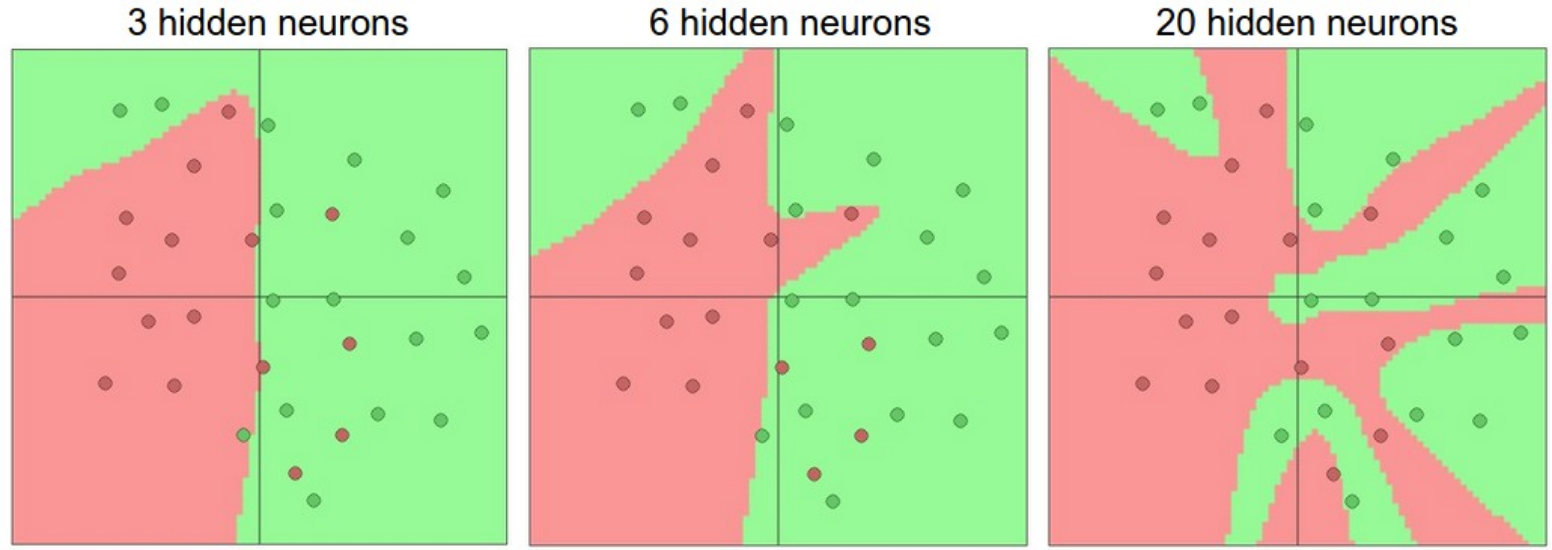
- Redes maiores modelam funções mais complexas
- Maior risco de overfitting
- Necessitam regularização adequada
Escolhendo Arquiteturas
- Mais camadas → maior abstração
- Maior custo computacional
- Mais neurônios → maior capacidade
- Regularização torna-se essencial
- Mede a capacidade da rede
- Redes modernas possuem milhões ou bilhões
Exemplos de arquiteturas
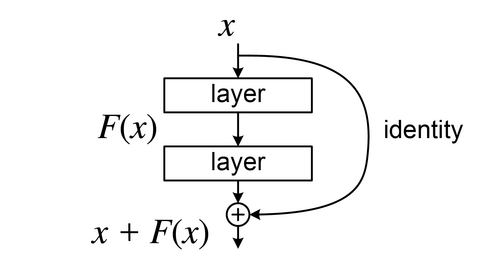
Problemas comuns
- Vanishing Gradients
- Exploding Gradients
- Learning Rate inadequada
- Má inicialização
Otimizadores Modernos
- SGD
- Momentum
- RMSProp
- Adam
Técnicas de Regularização
- Dropout
- L1/L2
- Early Stopping
- Data Augmentation
- Batch Normalization
Dropout
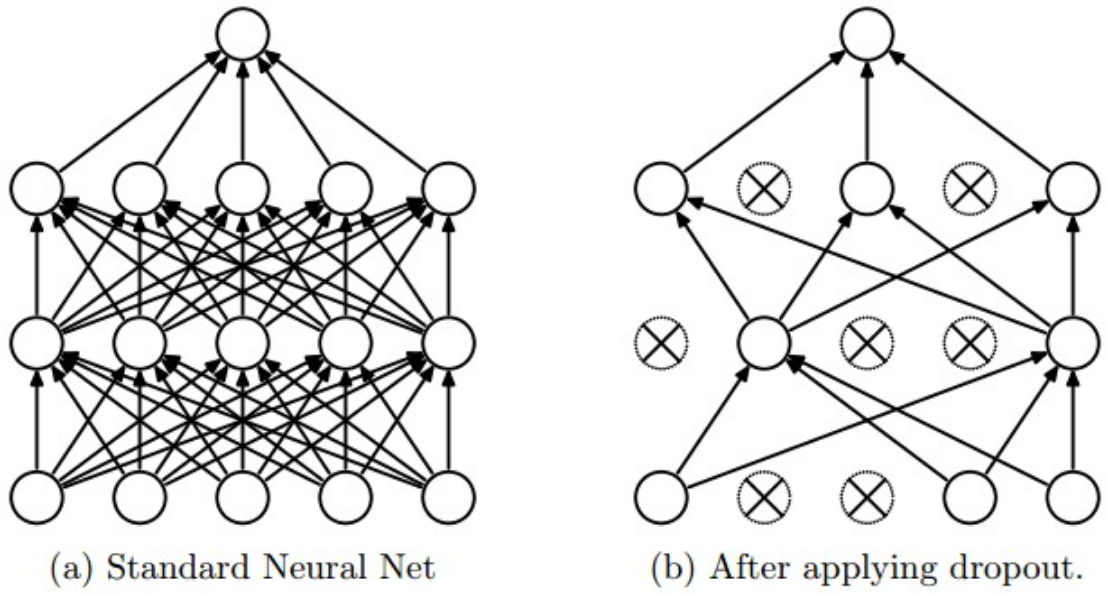
Batch Normalization
Batch Normalization é uma técnica que normaliza as ativações de cada mini-batch durante o treinamento.
- Vantagens
- Acelerar a convergência do treinamento
- Reduzir sensibilidade à inicialização
- Redução do vanishing/exploding gradient
- Maior robustez à inicialização
- Efeito regularizador moderado
- Melhor generalização
Problema: Internal Covariate Shift
Durante o treinamento, a distribuição das ativações muda continuamente à medida que os pesos são atualizados.
- Consequências
- Treinamento mais lento
- Gradientes instáveis
- Maior dificuldade de convergência
- Dependência crítica da inicialização
BatchNorm reduz esse efeito ao manter as ativações aproximadamente padronizadas.
Camadas Principais
- Dense
- Convolution
- Pooling
- Flatten
- Normalization
- Softmax
Redes Convolucionais
Processamento de Imagens
Por Que Não Usar Camadas Totalmente Conectadas?
Uma imagem de tamanho 200 × 200 × 3 possui:
Conectando-a a apenas 1.000 neurônios, seriam necessários:
- Consumo excessivo de memória
- Treinamento extremamente lento
- Grande risco de overfitting
Por Que CNNs Funcionam Tão Bem?
- Invariância a translações
- Aprendizado hierárquico de características
- Uso eficiente de parâmetros
- Excelente escalabilidade
Ideias Fundamentais das CNNs
- Conectividade Local
- Compartilhamento de Parâmetros
- Hierarquia Espacial de Características
Essas propriedades reduzem drasticamente a quantidade de parâmetros treináveis.
CNN são:
- Especializadas em imagens
- Extração automática de características
- Compartilhamento de pesos
Arquitetura Típica de uma CNN
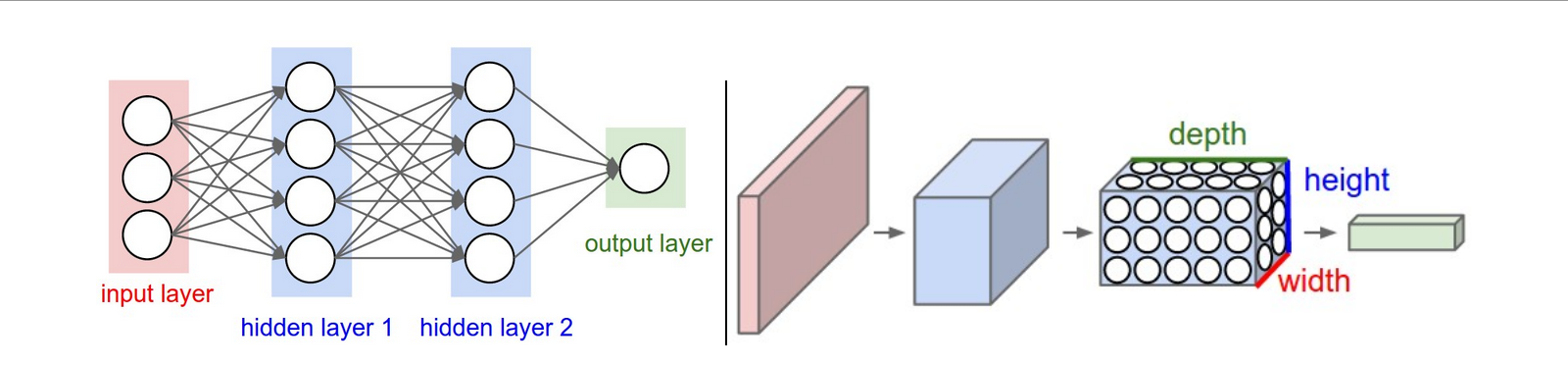
Volume de Entrada
Exemplo: imagem do CIFAR-10
- Largura
- Altura
- Profundidade (canais RGB)
Camada de Convolução
Aplica filtros aprendíveis sobre a imagem.
- F: tamanho do filtro
- S: stride (passo)
- P: padding
Ativações de uma arquitetura de ConvNet
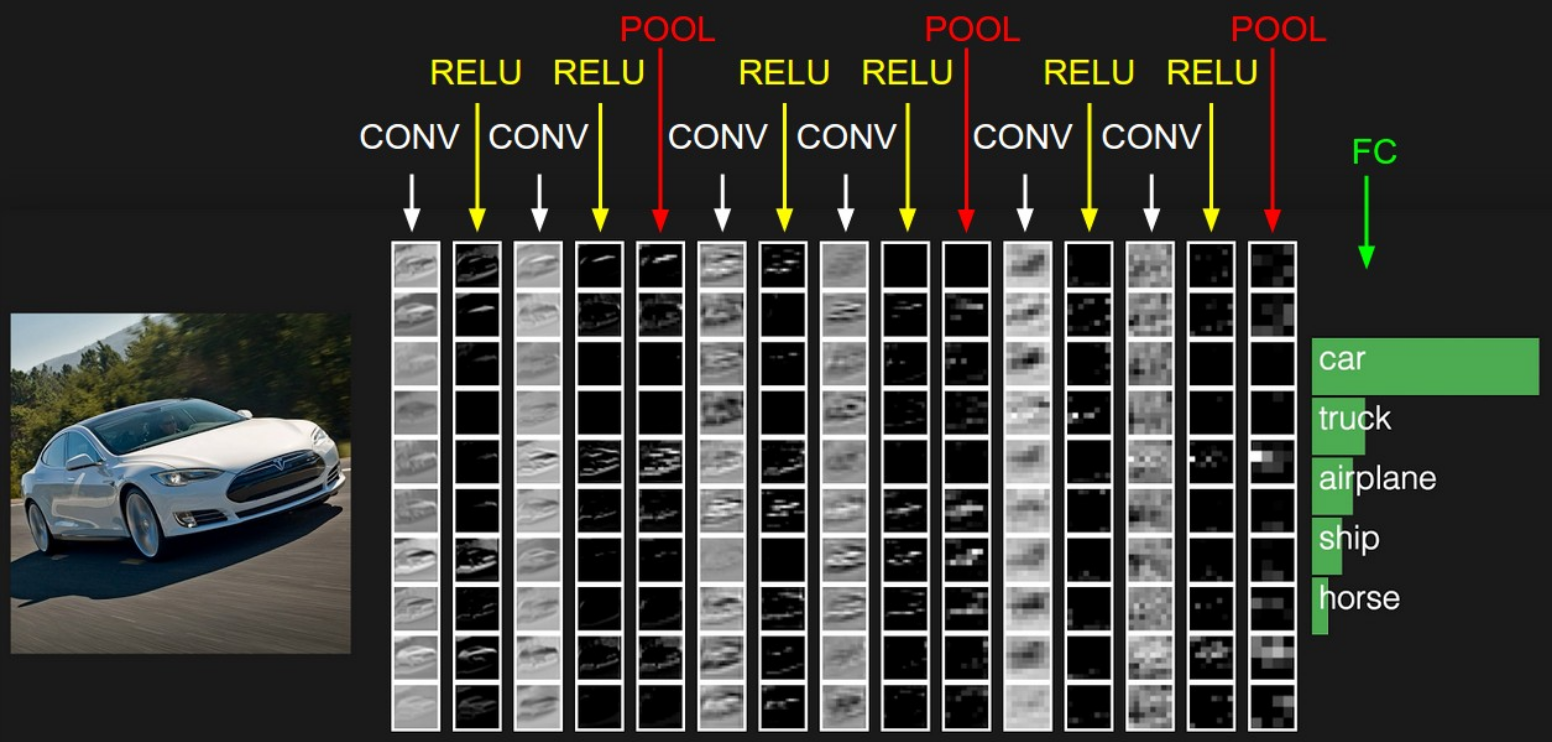
Exemplo de Convolução - Uma imagem CIFAR-10 de 32x32x3
O 5 neurônios observam a mesma região na entrada ao longo da profundidade, mas não compartilham os mesmos pesos.
Exemplo de Convolução - Uma imagem CIFAR-10 de 32x32x3
Features aprendidas

Camada de Pooling
- Reduz dimensionalidade
- Preserva características importantes
- Controlar overfitting
- É utilizada em cada camada de profundidade independentemente
Exemplo de Pooling - Entrada [224x224x64]
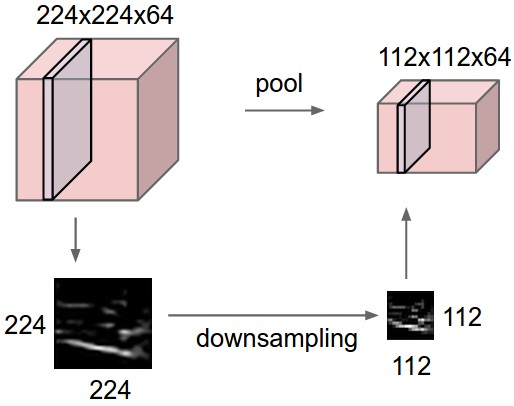
Exemplo de Pooling - Entrada [224x224x64]
Arquiteturas Clássicas
- LeNet (1998)
- AlexNet (2012)
- VGG (2014)
- GoogLeNet (2014)
- ResNet (2015)
Resumo
- Exploram a estrutura espacial das imagens
- Convoluções aprendem padrões locais
- Pooling reduz dimensionalidade
- Camadas densas classificam
- Base da visão computacional moderna
Redes Recorrentes
Processamento de Texto
Redes Recorrentes (RNN)
- Processam sequências
- Possuem memória temporal
LSTM e Gate Recurrent Units (GRU)
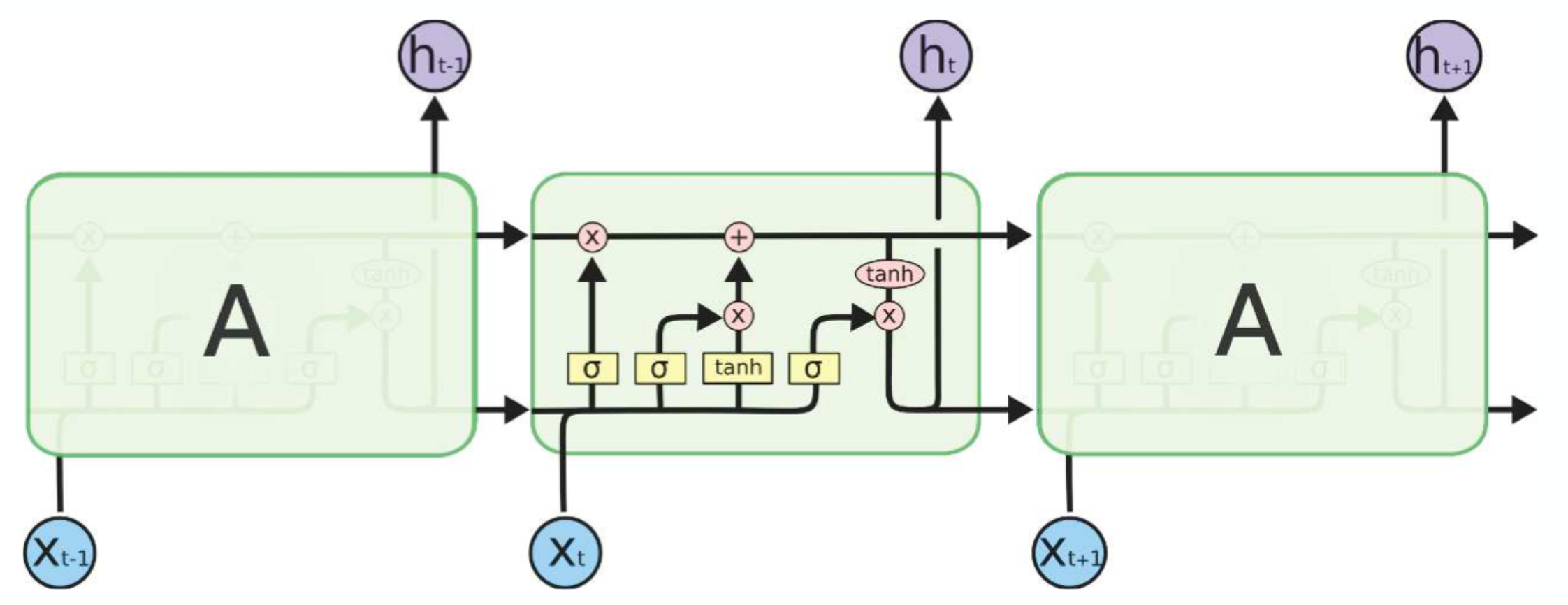
- Resolvem gradientes desaparecendo
- Excelente para séries temporais e NLP
Transformers
- Mecanismo de atenção
- Paralelização massiva
- Base dos LLMs modernos
Self-Attention
Aplicações
- Visão Computacional
- Processamento de Linguagem Natural
- Reconhecimento de Voz
- Sistemas de Recomendação
- Veículos Autônomos
- Medicina
Pipeline de Desenvolvimento
- Coleta de dados
- Pré-processamento
- Treinamento
- Validação
- Teste
- Deploy
Principais Desafios
- Grande volume de dados
- Alto custo computacional
- Escolha da arquitetura
- Interpretabilidade
- Viés algorítmico
- ATAI Yuri Lavinas, Sylvain Cussat-Blanc - UCT/M2-MIAGE 2IS
- MIT6.034 Patrick H. Winston https://ocw.mit.edu/courses/6-034-artificial-intelligence-fall-2010/
- Stanford CS class CS231n: Convolutional Neural Networks for Visual Recognition http://vision.stanford.edu/teaching/cs231n